Abstract
Recent methods have made notable progress in the visual quality of hand-object interaction
video synthesis. However, most approaches rely on 2D control signals that lack spatial
expressiveness and limit the utilization of synthetic 3D conditional data. To address these
limitations, we propose HVG-3D, a unified framework for 3D-aware
hand-object interaction (HOI) video synthesis conditioned on explicit 3D representations.
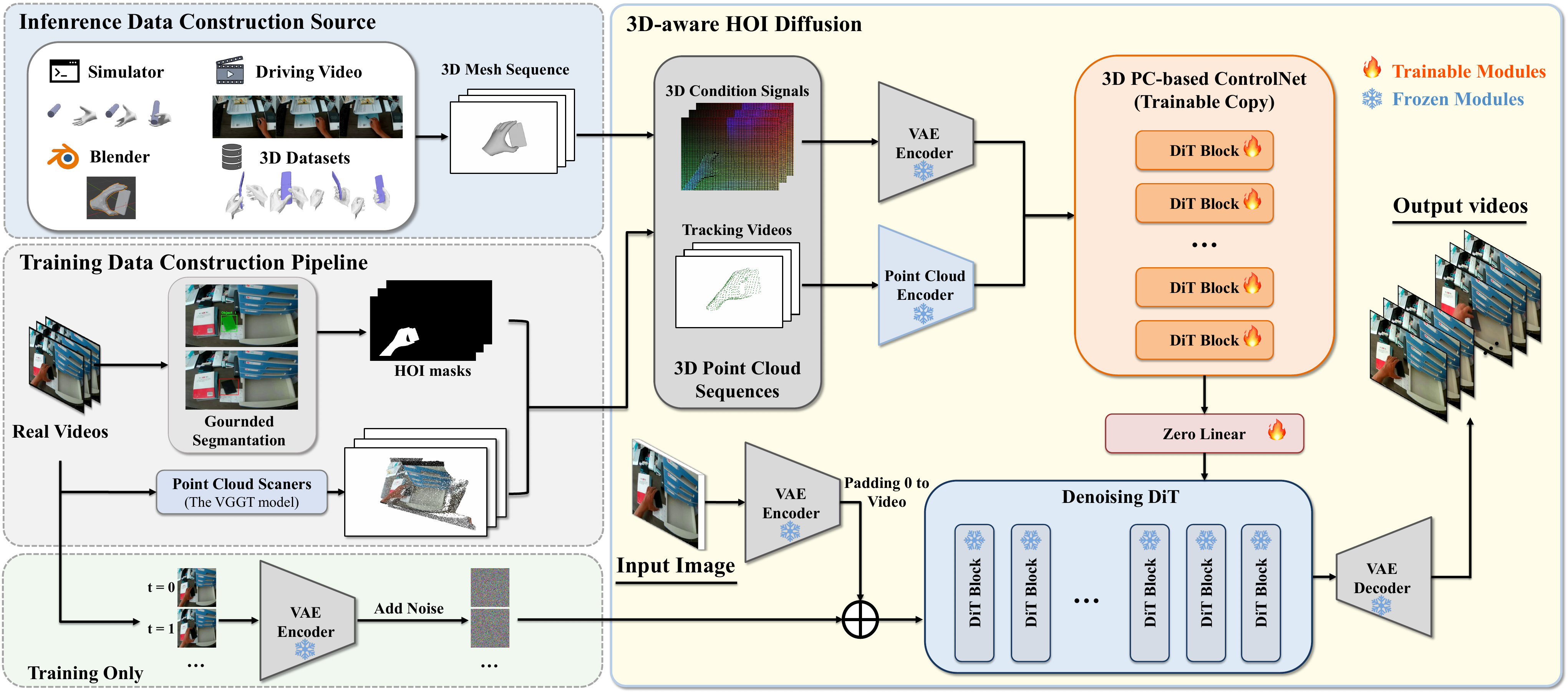
Specifically, we develop a diffusion-based architecture augmented with a 3D ControlNet,
which encodes geometric and motion cues from 3D inputs to enable explicit 3D reasoning
during video synthesis. To achieve high-quality synthesis, HVG-3D is designed with two
core components: (i) a 3D-aware HOI video generation diffusion architecture that
encodes geometric and motion cues from 3D inputs for explicit 3D reasoning; and
(ii) a hybrid pipeline for constructing input and condition signals, enabling
flexible and precise control during both training and inference. During inference, given a
single real image and a 3D control signal from either simulation or real data, HVG-3D
generates high-fidelity, temporally consistent videos with precise spatial and temporal
control. Experiments on the TASTE-Rob dataset demonstrate that HVG-3D achieves
state-of-the-art spatial fidelity, temporal coherence, and controllability, while enabling
effective utilization of both real and simulated data.